as the operand of a query expression (in a DECLARE CURSOR statement),
in a subquery within, for instance, a COMPARISON predicate,
Syntax:
A query specification is used to define a resultant table.
A query specification can appear in one of the following contexts:
as the operand of a query expression (in a DECLARE CURSOR statement),
in a subquery within, for instance, a COMPARISON predicate,
Syntax:
|
DISTINCT |
An optional directive which forces all rows of the resultant table to be unique, that is, duplicate rows will not be returned. |
|
ALL |
The default setting. Duplicate rows will be returned. |
|
derived-column |
The specification of the corresponding columns in the final resultant table derived by the query. Derived columns are separated by commas and all of them together are referred to as the derived column list (see separate diagram below). |
|
table-specification |
The specification of tables or views from which the resultant table is to be defined. Table and view names are separated by commas and all of them together are referred to as the table list. |
|
correlation-identifier |
Used to give an alternative name to a particular table for use within the query and subqueries which are in scope. |
|
WHERE clause |
The specification of a search condition which candidate rows must fulfill in order to become part of the resultant table. |
|
GROUP BY clause |
The specification of the desired grouping columns. A grouping column is the column by which the resultant table will be grouped. |
|
HAVING clause |
Specifies a search condition which candidate groups must fulfill in order to become part of the resultant table. |
|
correlation-identifier |
An alternative name to a particular table for use within the query and subqueries which are in scope. |
|
table-specification |
The specification of a table or view. The correlation identifier and table specification must be specified in the table list of the FROM clause. |
|
* |
Abbreviated form of listing all columns of the table identified by the correlation identifier or the table specification. If this is specified, all columns of all tables specified in the table list of the FROM clause are selected. . In ANSI compatibility mode, the qualification of the asterisk in the form of the correlation identifier or the table specification is not permitted. |
|
expression |
A valid expression as described in the section Expressions. |
|
column_title |
Identifies the derived column in the resultant table. |
A query specification:
defines the resultant table
specified in the derived column list
derived from the tables or views given in the table list,
subject to the conditions imposed by the optional WHERE and/or HAVING clause
and optionally grouped according to the GROUP BY clause.
Example:
The following describes the step-by-step processing of a query with the respective intermediate resultant tables. The abstract example uses a base table named T and columns named a, b, c and d. The apparent ordering of the intermediate resultant tables is due to ease of representation rather than of any predetermined ordering of the resultant tables.
SELECT a + 10, d, MAX(b) + 2
FROM T
WHERE c = 33
GROUP BY a, d
HAVING MIN(b) > 3;
The table list in the FROM clause actually defines all the candidate rows which may become part of the result. Conceptually, the first processing step of a query specification is to establish an intermediate resultant table containing all columns and all rows as defined in the table list. If only one table is involved, then the resultant table will be equivalent to the base table. However, should more than one table be listed, then all the tables in the list must be conceptually joined.
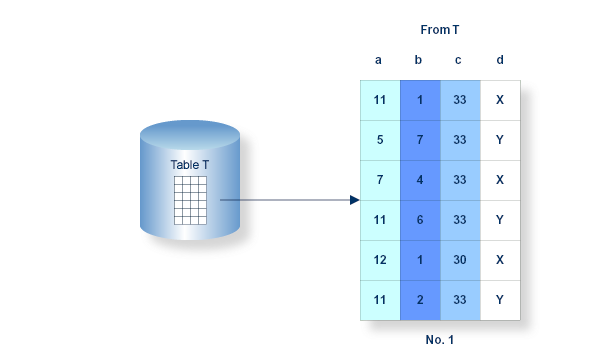
Figure for Processing Step 1
The next processing step concerns the WHERE clause. Each row in the intermediate resultant table is conceptually subjected to the search condition specified in the WHERE clause. If the condition equates to true, then the candidate row proceeds to the next stage. Otherwise, it is eliminated from further consideration, thus reducing the size of the final resultant table. Should no WHERE clause have been specified or the condition equate to true for all candidate rows then the subsequent resultant table will contain all rows as illustrated by the intermediate resultant table No.1.
Figure for Processing Step 2
The next possible processing step concerns the GROUP BY clause. This step actually splits into two phases resulting in Tables No. 3 and No. 4. If built-in functions are used within a query, it is called a grouped query. The query is also grouped if a GROUP BY clause is specified, even if no functions are given. Built-in functions are aggregate operators which operate on a set of values in order to produce a single value as a result. These functions can be applied to the whole intermediate resultant table in order to produce a final resultant table of one row. In such a case, no GROUP BY clause is specified but the query is still grouped, as it uses built-in functions. Any column referenced within a grouped query must be an operand of a function, a grouping column or appear anywhere in the WHERE clause. This is because outside of the WHERE clause, the query is concerned with groups instead of mere rows. The converse, however, is not true. A grouping column may appear in a function. In the case of a special register, it must be specified exactly the same way as it appears in the SELECT list.
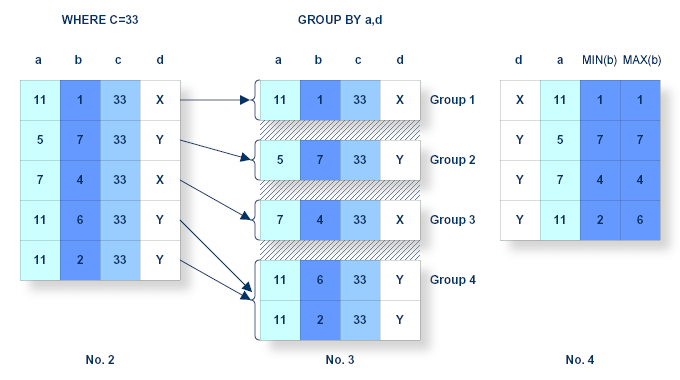
Figure for Processing Step 3
It is possible to divide the intermediate resultant table into groups. Groups are partitioned by specifying at least one grouping column in the GROUP BY list. A group is then established by extracting all candidate rows from the intermediate resultant table No. 2, where the value of the grouping column/s is/are equal. As many groups are established as there are differing values of the grouping column. There is no predetermined ordering of these groups.
Groups are established as follows:
identical values in the first grouping column are identified,
if a match has been made, the values of the second grouping columns are compared (same procedure for all other grouping columns),
if all values in the grouping columns are identical, a candidate row has been identified.
At this point the second phase is initiated. The query is examined in order to produce a list of the columns required for intermediate resultant table No. 4. These new columns are either grouping columns or columns derived from functions applied to columns in intermediate resultant table No. 3. In either case, only columns or functions appearing in the derived column list or the HAVING clause have to be considered. Thus, aggregate functions are applied to each group in turn resulting in one candidate row per group in intermediate resultant table No. 4.
The aggregate functions can now be applied to each group in turn resulting in one candidate row per group for the next conceptual intermediate table.
In conclusion, the GROUP BY clause establishes candidate groups which, when operated upon by the aggregate functions, are transformed into candidate rows, one per group, which form the next intermediate resultant table No. 4.
The next possible processing step concerns the HAVING clause . Each row in the intermediate resultant table is conceptually subjected to the search condition specified in the HAVING clause. If the condition equates to true, then the candidate row proceeds to the next stage, otherwise it is eliminated from further consideration. As such, it is analogous to the WHERE clause except it eliminates candidate groups rather than candidate rows. It is therefore permissible to use functions in the search conditions. In fact, columns which are not contained in a function must be specified in the GROUP BY list.
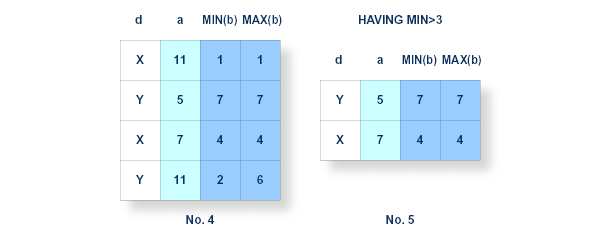
Figure for Processing Step 4
The final stage can now be executed, namely the production of the final resultant table . This is a derivation of the previous intermediate resultant table and is conceptually the same, regardless of whether it came from the HAVING, GROUP BY, WHERE or FROM clause. A resultant row is processed by evaluating each derived column in turn, based on the values contained in the corresponding row of the intermediate resultant table. This evaluation may be quite complex, depending on the nature of the expressions contained in the derived column's specification.
Step 5 finalizes the processing of this query by producing the final resultant table no. 6.
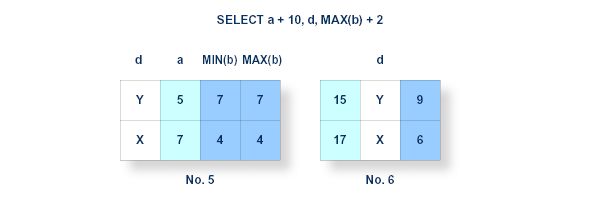
Figure for Processing Step 5
A derived column list of at least one derived column must be specified. This may be done either as explicit expressions separated by commas or as an asterisk. The asterisk is an abbreviation representing all the columns as defined in the table list. An equivalent statement would simply list all columns explicitly, in the order in which they were defined in the original CREATE TABLE statement.
It is also possible to qualify the asterisk with a table specification which will result in all the columns belonging to the specified table only being derived.
Each derived column has an associated data type which is projected out of the subquery. The derived column may also have an identifier by which the derived column can be identified externally to the query specification e.g. from within an ORDER BY clause. If the derived column is based exclusively on a column of a base table, the identifier is the name of the column, in which case the derived column label is simply the fully qualified column specification. For all types of derived columns a new identifier can be specified with the 'AS<column identifier>' subclause.
It should be noted that the use of an asterisk with a table list made up of more than one table can lead to extremely large derived column lists.
A query specification must have at least one table or view listed in the FROM clause. All column references must uniquely refer to one of these table references. If the same column name is present in more than one table in the FROM clause then it must be qualified by the appropriate table name, which itself may need to be explicitly qualified (see Table Specification for details).
A table reference is in scope not only within the actual query specification in which it is declared but also for all subqueries that occur as part of this query specification. That is until the table is declared again in a lower subquery in which case columns referring to this table refer to the local declaration and not the outer one. Columns which refer to tables declared in an outer query specification are called outer references.
Should more than one table be declared in the FROM clause, then the query is said to be joined. It is possible for a table to be joined with itself but in such a case, in order to make the table references unique within the FROM clause, at least one correlation name must be given.
A subquery is a query specification which is subordinate to or nested in another query specification. In general, a subquery is also the origin of a value or a set of values. If this is the case, the number of derived columns in the derived column list of the query specification must be exactly one. The data type and length of such a value resulting from a subquery is the data type and length of that derived column.
A correlation name is a means of giving an alternative label to a table within the query specification. Hence, if a column reference is qualified with the table name and a correlation name has been specified, then the qualification must be the correlation name.
A subquery may only return a derived column list with a cardinality of one. Within an unquantified COMPARISON predicate only one value may be returned. Please refer to COMPARISON, IN and EXISTS predicates for more details.
Columns which are specified in grouped queries but are not themselves specified in functions are grouping columns and hence, must be listed in the GROUP BY list. This is only necessary for columns appearing either in the derived column list or in the HAVING clause, regardless of if they are referenced in a subquery of the grouped query or not. If there are no such columns then a GROUP BY list is not required, i.e the whole intermediate resultant table is considered to be a group. However one may be given if desired.
A grouped query which is derived from a view can not reference columns from that view in any kind of expression.
A DISTINCT directive may only appear once within the subquery. Hence, if the derived column list has been specified as DISTINCT then no functions may also be specified with DISTINCT, whether they are in the derived column list, in the HAVING clause or even in a contained subquery.
The keyword BY is mandatory in a GROUP BY clause.
Examples
The following example selects all contracts and associated cruise identifiers for all cruises booked on August 12th, 2002.
SELECT contract_id,id_cruise
FROM contract
WHERE date_booking = 20020812;
The following example creates a list of the different start harbors available.
SELECT DISTINCT start_harbor
FROM cruise ;
The following example identifies all the contract IDs, customer IDs and cruise prices of all cruises that leave from Bahamas.
SELECT contract.contract_id, contract.id_customer,
cruise.cruise_price
FROM contract,cruise
WHERE cruise.start_harbor = 'BAHAMAS'
and contract.id_cruise = cruise.cruise_id;
The following example selects the most expensive and least expensive cruise going to either Fethiye or Bodrum from Marmaris:
SELECT start_harbor,
destination_harbor,
MAX(cruise_price),
MIN(cruise_price)
FROM cruise
WHERE start_harbor = 'MARMARIS'
GROUP BY start_harbor,destination_harbor
HAVING destination_harbor = 'FETHIYE'
OR destination_harbor = 'BODRUM' ;
Also see the detailed, illustrated examples earlier within this section.